123
ПОИСК СЛОЖНОЙ ИНФОРМАЦИИ У ЧЕЛОВЕКА В СЕМАНТИЧЕСКОЙ ПАМЯТИ
К.М. ШОЛОМИЙ
1. ВВЕДЕНИЕ
Сложные формы человеческого поведения требуют владения значительным объемом информации. В этой связи возникают определенные трудности, неоднократно отмечавшиеся в литературе.
Так, И. Рок, исходя из того, что впечатление знакомости, возникающее при узнавании, обусловлено соотнесением, сличением восприятия и следа, пишет: «Если предположить, что следы в памяти сохраняются в течение длительного времени, то в нервной системе хранится огромное число следов различных объектов и событий, воспринимавшихся в течение всей жизни. Узнавание чего-либо означает, что возбуждаются релевантные следы этих объектов. Мы не понимаем, как происходит этот удивительный и почти мгновенный выбор...» [15; 43]. Р. Кладки говорит об огромном «количестве хранящихся в памяти эталонов» [9; 69]. Б.М. Величковский называет «удивительным» тот факт, что за время около одной секунды человек может определить отсутствие слова «мантинас» и т.е. среди 104— 105 слов родного языка [3; 190]. А.П. Линдсей и Д. Норман дают даже количественную характеристику проблемы: «Главный источник трудностей, связанных с долговременной памятью, — это проблема поиска информации. Количество информации, содержащейся в памяти, очень велико, и поэтому извлечение из нее именно тех сведений, которые требуются в данный момент, сопряжено с серьезными трудностями... Проблемы, связанные со способностью найти единственно правильную единицу среди хранящихся в памяти миллионов или миллиардов их, в большой степени определяют общую структуру всех ступеней системы памяти» [13; 279].
Содержащаяся в приведенных цитатах оценка объема поиска в памяти имеет интуитивный характер. Обосновывающих данных авторы не приводят, нет их, насколько нам известно, и в литературе (если не считать подсчеты в битах, неадекватность которых по отношению к психическим реальностям давно уже показана [2], [10]). И все же эта оценка справедлива. В реальной жизни человек часто сталкивается с ситуациями, когда ему действительно приходится дифференцировать миллионы стимулов.
Покажем это на конкретном примере. Подсчитаем приблизительно количество разных словоупотреблений, т.е. разных слов в различных грамматических формах, которые дифференцирует человек при чтении художественной литературы.
Для проведения подсчета необходимо прежде всего знать объем пассивной лексики, которой владеет человек. Поскольку такие данные в литературе отсутствуют, на кафедре психологии МГПИИЯ им. М. Тореза под нашим руководством был проведен соответствующий эксперимент. Из словаря русского языка [14] объемом 110 тыс. слов была извлечена выборка, позволяющая с ошибкой ±7 % судить о знании всех слов словаря. Испытуемых просили определять слова выборки или образовывать с ними предложения. Полученные данные позволяют считать, что взрослые испытуемые с высшим образованием знают в среднем около 80 тыс. слов словаря, использовавшегося в эксперименте (±7700). Но в действительности их словарный запас, конечно, больше1. В качестве первого приближения примем здесь, что он составляет 100 тыс. слов.
124
Примем, далее, что частота основных классов слов в словаре такая же, как в тексте: глагол — 25 %, существительное — 37,5 %, прилагательное — 16 % [20]. Отсюда, с учетом некоторых упрощающих допущений, получим следующее распределение: переходные глаголы 17 500, непереходные — 5000, возвратные — 2500, существительные — 37 500, прилагательные — 16 000. Чтобы определить, сколько словоупотреблений допускает некоторый класс слов, достаточно умножить количество составляющих его слов на количество грамматических форм, которые эти слова могут принимать. Для определения количества форм воспользуемся данными немецкой грамматики (соответствующими данными русской грамматики автор не располагает). Обусловленное этим изменение результата подсчета не может быть значительным ввиду известного сходства русской грамматики с немецкой.
Поясним принцип подсчета на примере класса слов, наиболее богатых грамматическими характеристиками, — переходных глаголов. Возможные грамматические формы сведены в табл. 1. Переходный глагол в немецком языке изменяется по временам, числам, лицам, наклонениям и залогам. Для удобства подсчета пришлось ввести не представленное в грамматике разбиение форм глагола на поливременные (имеющие несколько времен) и моновременные (имеющие одно время) Как видно из таблицы, число форм, которые может принимать каждый переходный глагол, составляет 221. Таким образом, общее количество разных употреблений составляет: 17 500∙221 = 3 867 500.
Таблица 1
Подсчет грамматических форм переходного глагола в немецком языке
|
№ п/п |
Грамматические категории |
Страдательный залог |
Действительный залог |
|||||
|
Поливременные формы |
Моновременные формы (кондиционалис) |
Поливременные формы |
Моновременные формы |
|||||
|
Пассив действия |
Пассив результативный |
Пассив безличный |
Кондиционалис |
Повелительное наклонение |
||||
|
1 |
Время |
6 |
3 |
6 |
1 |
6 |
1 |
1 |
|
2 |
Число |
2 |
2 |
1 |
2 |
2 |
2 |
2 |
|
3 |
Лицо |
3 |
3 |
1 |
3 |
3 |
3 |
2 ед. ч |
|
|
|
|
|
|
|
|
|
3 мн. ч |
|
4 |
Наклонение |
2 |
2 |
2 |
2 |
2 |
2 |
1 |
|
|
Всего |
72 |
36 |
12 |
12 |
72 |
12 |
5 |
|
|
Итого |
221 |
||||||
Подсчитав грамматические формы по остальным классам слов, получим: непереходные глаголы — 100, возвратные глаголы — 88, модальные глаголы с инфинитивом: а) действительный и страдательный залоги с инфинитивом I — 288, б) действительный залог с инфинитивом II — 144, в) страдательный залог с инфинитивом II — 144, глагол haben в модальном значении — 24, sein в модальном значении — 24, прилагательные — 192, существительные — 20. Соответственно общее количество возможных словоупотреблений будет таким: 20 103 000.
При чтении человек распознает воспринятое словоупотребление как элемент известного ему словаря, т.е. как носителя определенного понятия, а также как носителя грамматических характеристик, определяемых формой словоупотребления. Но чтобы это произошло, в памяти должна быть найдена соответствующая часть ее содержания, некоторая единица памяти, активация которой переживается человеком как владение этой совокупной информацией [16], т.е. как понимание словоупотребления, позволяющее интерпретировать его как компонент читаемого текста. Ясно, что число таких единиц памяти должно соответствовать количеству возможных словоупотреблений. Содержание памяти, обеспечивающее возможность чтения, является, таким образом, если воспользоваться кибернетической терминологией, большой, или сложной, системой [7].
Очевидно, что сложносистемность чтения не является каким-то исключением, скорее — наоборот Умение читать формируется в течение нескольких лет. Естественно предположить, что и в других Случаях, когда обучение имеет аналогичную длительность, аналогичными будут и масштабы формируемых содержаний памяти. Но обучение, длящееся годами, — норма в современной жизни. Следовательно, содержания памяти, которыми оперирует человек в повседневной практике, часто являются большими системами.
Итак, возникает вопрос: как психика преодолевает «чудовищность» задачи сканирования всех следов памяти [15; 43], как удается человеку достаточно быстро
125
находить среди миллионов единиц памяти требуемую?
Как уже отмечалось, этот вопрос еще не решен. Поиску информации в памяти посвящена обширная литература, и существует несколько десятков моделей переработки информации при решении этой задачи [3; 75]. Особую популярность приобрела модель С. Стернберга [25], предусматривающая линейно-последовательную процедуру сравнения. Имеются также модели, включающие параллельные процессы [26] и «прямой доступ» [1], [8]. В уравнениях, аппроксимирующих время реакции, используется логарифмическая зависимость, которая иногда принимается как свидетельство в пользу иерархической или параллельной организации процесса поиска [8]. Идея иерархической организации используется также при постулировании смешанного типа поиска, когда одна часть процессов протекает параллельно, а другая — последовательно [6], [17], [23]. Однако существующие подходы к проблеме поиска в памяти строятся преимущественно на основе данных малосистемных исследований, когда алфавит стимулов (положительное множество) имеет незначительную величину. Обычно эта величина около 10, десятки стимулов используются редко (Р. Аткинсон называет наборы из 60 и более стимулов «очень большими» [1; 307]), а уровень сотен или тысяч, встречающийся в единичных случаях ([8], [22], [24]), по-видимому, является пока пределом. Но экстраполяция результатов малосистемных исследований на сложносистемные ситуации часто неправомерна2 и вряд ли может служить основой для ответа на поставленный вопрос.
Мы попытаемся показать, что для ответа на него достаточной является модель, предусматривающая последовательную процедуру сравнения при иерархической организации памяти.
2. ИЕРАРХИЧЕСКАЯ ОРГАНИЗАЦИЯ КАК ФАКТОР ОБЛЕГЧЕНИЯ РАБОТЫ ПАМЯТИ
Известно, что знания хранятся в памяти в виде сложной, иерархически организованной системы понятий, в которой они различаются по степени обобщенности и связаны родовидовыми отношениями. В таком отношении находятся, например, понятия «растение», «цветок», «роза» [5; 270].
В последнее время феномен иерархической организации памяти все чаще начинает привлекать внимание исследователей. Показано, что она обусловливает повышение эффективности запоминания [21]. Однако соответствующие исследования проводятся, как правило, на малосистемном уровне.
Приведем типичный эксперимент [27]. Исследовалось запоминание четырех списков слов, состоящих из 24 слов каждый. Слова первого списка в наибольшей степени связаны иерархической зависимостью; половина графа, описывающего эту зависимость, представлена на рис. 1 (слова обозначены числами). На самом нижнем уровне иерархии они упорядочены с учетом феномена типичности [3], [21], затем соответственно понятиям: «птицы», «рыбы», «плоды» и т.п., далее понятиям «животные», «растения», «напитки», «минералы», наконец, «живое», «неживое». Путем трансформации этого исходного списка, последовательно устраняющей один уровень иерархии за другим, были составлены еще четыре списка, так что число уровней иерархии в списках менялось, от пяти до одного, т.е. до полностью случайного расположения слов. Результаты эксперимента показывают, что по мере увеличения иерархичности структуры списка трудность его запоминания отчетливо уменьшается (описано по [21; 199]).
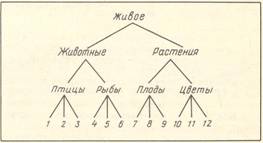
Рис. 1. Иерархическая организация исходного списка слов в эксперименте Ундервуда и др. [27]. Изображена половина графа, описывающего эту организацию. Слова представлены числами
Ниже мы попытаемся охарактеризовать облегчающую функцию иерархии по отношению
126
к сложносистемной ситуации в общем виде. Для этого сопоставим поиск в памяти при решении одних и тех же задач, а именно задач на распознавание, в условиях, когда память лишена иерархической организации (ср. модель С. Стернберга) и когда такая организация налицо. Таким образом, будет определена «прибавка», обусловленная фактом появления иерархической организации.
Будем исходить из того, что у субъекта в результате обучения сформирован психический механизм, обеспечивающий распознавание требуемых объектов. Схему его работы можно охарактеризовать следующим образом.
Воспринятый материал о внешнем предмете, стимуле, принадлежащем к одному из п альтернативных классов, которые обозначим через Y1, Y2, ..., Yn, подвергается предварительной обработке на сенсорном уровне. Полученное при этом признаковое представление стимула сличается в ходе поиска с набором кодов (перцептивных и/или концептуальных) или эталонов, составляющих содержание семантической памяти и переживаемых как знание о признаках предметов3. По результатам сличения распознающий механизм «принимает решение» о принадлежности воспринятого предмета к тому или иному из упомянутых классов [8], [9], [13], [17], [21]. Схема отражает только главные черты опознавательного процесса и абстрагируется от деталей его микрогенеза [17].
Представим составляющие эталоны системы признаков для обоих сопоставляемых случаев в виде деревьев признаков. Деревья, изображающие в общем виде неиерархическую и иерархическую системы признаков, представлены на рис. 2, а, б.
На ярусах дерева признаков могут располагаться признаки как одной, так и нескольких категорий. Последний случай представлен деревом, показанным на рис. 1. Будем называть такие системы поликатегориальными, системы же, у которых на каждом ярусе находятся признаки только одной категории, — монокатегориальными (рис. 2, б); термины «поликатегориальный» и «монокатегориальный» заимствованы из работы [12]. Можно, далее, говорить о симметричных и несимметричных системах соответственно тому, что число признаков каждой категории может быть одинаковым для системы или варьировать. Ограничимся здесь рассмотрением только симметричных систем.
Использованные при построении моделей символы имеют следующие значения:
n — число альтернативных классов; π — признак; а — размер категории, т.е. количество разных признаков, находящихся на ярусе; m — число ярусов; u — число путей или маршрутов на дереве; х — представленный для распознавания объект; Yi -обозначения альтернативных классов (i = 1,2, ..., n). Деревья можно рассматривать и как модели семантической памяти [6], и как модели процесса распознавания. В первом случае символы на ярусах интерпретируются как эталоны памяти, во втором — как положительные результаты сличения, т.е. как свидетельства наличия у распознаваемого предмета соответствующих признаков; штриховая линия между концевой точкой маршрута и обозначением класса символизирует логическую связку «если..., то».
Для симметричной монокатегориальной системы величины u, а и m связаны простым соотношением
u=am . (1)
Чтобы упростить анализ, будем рассматривать только системы, для которых
u=n. (2)
Уточним теперь параметры, по которым будет производиться сопоставление.
Величина V алфавита признаков, т.е. количество разных признаков, обеспечивающих распознавание всех требуемых объектов.
Количество операций сличения, выполняемых при распознавании. Чтобы облегчить определение этого параметра, будем рассматривать не все множество возможных стимулов, а достаточно представительную его часть, которую назовем циклом и определим так: цикл — множество стимулов, в котором присутствуют по одному предмету каждого из альтернативных классов Y1, ..., Yn. Теперь в качестве характеристики процесса распознавания можно принять Т — среднее количество операций сличения при распознавании цикла.
127
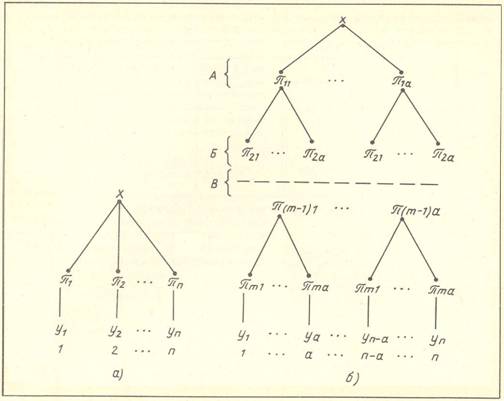
Рис. 2. Неиерархическая (а) и иерархическая симметричная монокатегориальная (б) системы признаков в общем виде
х — опознаваемый объект, Yi — альтернативные классы, отнесение к которым является целью распознавания, i=1, 2, …, n — номера маршрутов систем, π1, π2, …, πn, — признаки неиерархической системы, А, Б — первый и второй ярусы иерархической системы признаков, В — k-й уровень (k=1, 2, …, m), π11 — первый признак первого яруса, π12 — первый признак второго яруса, πm1 — первый признак последнего (m-го) яруса.
Определим V и Т для сопоставляемых случаев в условиях, когда человек выполняет задачу распознавания цикла.
1 Неиерархическая система. Множество признаков изоморфно множеству классов, т.е. каждому признаку соответствует определенный класс. Поэтому для распознавания предметов, принадлежащих к n классам, потребуется точно n разных признаков, т.е.
Vнeиep = n. (3)
Т определим из рассмотрения процедуры сличения. Распознающий механизм сравнивает с воспринятой информацией последовательно все имеющиеся признаки, пока не произойдет совпадение. Признаки берутся для сличения в фиксированной последовательности. При самооканчивающейся процедуре поиска всего за цикл будет выполнено —n(n+1)/2, при исчерпывающей — n2 операций, а в среднем за цикл:
Tнеиер, само = n(n+1)/2, Tнеиер, исч=n.
Иерархическая монокатегориальная система. Для определения V подсчет проведем по ярусам (рис. 2, б). На первом ярусе находятся а разных признаков. Число признаков на втором ярусе больше, но разных столько же. То же можно сказать и о всех последующих ярусах до m-го включительно. Всего разных признаков в системе будет
Vмоно=ma. (4)
Процедуру сравнения можно охарактеризовать так. Вначале она осуществляется в пределах признаков, находящихся на первом ярусе; признаки сопоставляются в фиксированной последовательности. Определив, каким признаком первого яруса обладает воспринятый предмет, распознающий механизм переходит к признакам второго яруса и т.д., до m-го яруса. Сличения на каждом ярусе осуществляются по той же схеме, что и при неиерархической системе признаков, и в среднем за цикл выполняется
128
½ (а+1) или а операций сличения. Соответственно, для m-ярусной системы
Tмоно, само = ½ m(а+1), Tмоно, исч=ma. (5)
Иерархическая поликатегориальная система. На первом ярусе находится а признаков, на втором — а2 (см. рис. 1, а), на m-м — аm. Итак:
Vполи=a + a2+...+am. (6)
Работа сличения будет, очевидно, такой же, как и в случае монокатегориальной системы:
Тполи, само= ½ m(а+1), Тполи, исч=mа. (7)
Чтобы облегчить сопоставление, унифицируем математическую форму полученных характеристик. Из (1) и (2) имеем:
n=am. (8)
Теперь все переменные можно выразить через m и а. Полученные результаты сведены в табл. 2.
Таблица 2
Признаковый алфавит и работа поиска как характеристики неиерархической и иерархической организации памяти
|
Вид системы |
Алфавит признаков V |
Среднее количество операций сличения Т |
||||
|
В общем случае |
При чтении |
В общем случае |
При чтении |
|||
|
Самооканчивание |
Исчерпывание |
Самооканчивание |
Исчерпывание |
|||
|
Неиерархическая |
аm |
20·106 |
½ am |
аm |
10·106 |
20·106 |
|
Иерархическая монокатегориальная |
am |
48 |
½ m (а+1) |
am |
32 |
48 |
|
Иерархическая поликатегориальная |
а+ ... + аm |
20·106 |
½ m (а+1) |
am |
32 |
48 |
В таблице представлены значения V и Т для случаев неиерархической и иерархической (монокатегориальной и поликатегориальной) организации памяти в общем случае и с учетом полученных выше характеристик процесса чтения4. Работа поиска указана для самооканчивающейся и исчерпывающей процедур. В выражении n+1 единицей пренебрегаем. При получении численных данных принято, что а=3.
Это допущение имеет серьезное основание: для монокатегориальной системы а=3 является условием минимизации алфавита признаков. Покажем это. Примем, что n=с (9), где с — некоторая константа, a m и а варьируют, и требуется найти такое а, чтобы алфавит V=ma был минимальным. Из соотношений (8) и (9) имеем:
m=c1/ln a, где c1 = ln с.
Подставив значение m в выражение алфавита и продифференцировав, получаем:
![]()
откуда а=2,71. Округляя, так как а может иметь только целочисленные значения, получим: минимальным алфавит признаков будет при а=3.
Этот математический вывод имеет, можно думать, прямое отношение к структуре семантической памяти. Психика — продукт миллионов лет эволюции, и естественно считать, что под действием отбора в ней сложилась тенденция к самосовершенствованию, к формированию и закреплению более рациональных структур и процессов [11], [18]. Следовательно, есть основания считать, что преимущество троичной организации получило какое-то отражение в структуре памяти, например в том смысле, что в формируемых в ней иерархических системах эталонов троичные категории признаков встречаются чаще, чем нетроичные, так что размерность категорий в среднем оказывается близкой к трем.
Данные табл. 2 обнаруживают закономерность, нарушаемую только поликатегориальной иерархической системой в отношении алфавита признаков. У нее алфавит больше, чем у неиерархической, т.е. применение поликатегориальности всегда приводит к увеличению алфавита. Формульные выражения для неиерархической и иерархической систем различаются тем, что в первом случае они образуют степень, а во втором — произведение. Степень всегда (кроме случая m=2 и а=2) больше произведения, поэтому
129
в отношении работы поиска иерархические системы обоих видов, а в отношении алфавита признаков — монокатегориальная всегда превосходят неиерархическую, причем различие бывает огромным. Например, процесс чтения может быть в принципе реализован на основе как иерархической, так и неиерархической систем, но в первом случае для этого потребуется запомнить в сотни тысяч раз меньше признаков и выполнить в сотни тысяч раз меньше поисковых операций, чем во втором.
3. ВРЕМЯ РЕАКЦИИ ПРИ СЛОЖНОСИСТЕМНОМ ПОИСКЕ
Полученные данные позволяют определить зависимость времени реакции от величины алфавита стимулов для сложно-системной ситуации.
Как известно, в общем случае при распознавании время реакции ВР можно представить следующим образом:
BP=t0+tn,
где t0 — время, обусловленное инвариантными для данных условий факторами (процесс кодирования и принятия решения, различимость стимулов и т.п. [1], [8]), tn — время, затрачиваемое на выполнение процедуры поиска. В нашем случае
tпо=qT,
где q — время выполнения одной операции сравнения. Представим Т как функцию n. Из (1) и (2) имеем:
![]()
Подставив это в выражения Т (5) и приняв а=3, получим:
Тсамо=4,2 lg n, Тисч=6,3 lg n.
Имея достаточно большое количество значений ВР, полученных экспериментальным путем, и задавшись подходящим значением q (оно, по-видимому, зависит от вида материала [8]), величину t0 можно определить путем оценки разностей ВР — tn.
Построим в качестве примера интересующие нас зависимости, воспользовавшись данными Л. Стэндинга [24]. В хронометрической части своего эксперимента он предъявлял испытуемым последовательности по 5, 10, 20, 40, 80 и 160 слов. При тестировании предъявлялись пары слов, из которых одно входило в ознакомительную последовательность, а другое — нет. Испытуемый сигнализировал об узнавании слова нажатием ключа. Данные Л. Стэндинга приведены в табл. 3.
Таблица 3
Время узнавания слов в эксперименте Л. Стэндинга
|
№ п/п |
n |
ВР мс |
|
1 |
5 |
567 |
|
2 |
10 |
675 |
|
3 |
20 |
738 |
|
4 |
40 |
753 |
|
5 |
80 |
780 |
|
6 |
160 |
825 |
Приняв q=37,9 мс [8] и определив t0, получаем:
BPсамо=490+159 lg n мс, ВРисч = 401+239 lg n мс.
Для ориентировочной проверки полученных зависимостей сопоставим время ответа на вопрос, являются ли словами квазислова типа «мантинас», полученные в эксперименте и с помощью этих зависимостей. Как уже отмечалось, в первом случае время составляет около одной секунды [3; 190]. Ответ на этот вопрос требует обследования всего субъективного лексикона, т.е. n=105 (см. «Введение»). Итак,
BPсамо=1285 мс, ВРисч=1596 мс.
Совпадение, на наш взгляд, удовлетворительное. Отметим также, что результат свидетельствует в пользу самооканчивающегося процесса.
Вычислим с помощью полученных зависимостей также время ответа для случая, когда будут предъявляться квазисловоупотребления типа «мантинасу», «глокая», «будланули», «штеких» и т.п. Областью поиска будет теперь все множество возможных словоупотреблений, т.е. n=20·106. Имеем:
BPсамо=166O мс, ВРисч=2161 мс.
Результат, можно думать, интуитивно приемлемый.
Было бы интересно проверить реалистичность описанной модели путем сопоставления ее с данными нескольких экспериментальных исследований. Но исследований, посвященных хронометрическому анализу сложносистемного поиска в памяти, в настоящее время очень мало. Кроме двух упомянутых выше работ, нам не известны другие работы, результаты которых имело бы смысл сопоставлять с моделью. Для ее полноценной проверки требуется специальный эксперимент.
130
ЗАКЛЮЧЕНИЕ
Итак, на вопрос о том, как психика справляется с трудностями сложносистемного поиска в памяти, можно, в первом приближении, дать следующий ответ: в значительной, а может быть, и в решающей степени за счет его иерархической организации. Несомненно, значительную роль играет также контекст и другие способы рационализации умственной деятельности, но главным, определяющим фактором является все же иерархическая организация. Слишком велика ее мощь и слишком прост механизм, чтобы она осталась «не замеченной» в течение миллионов лет эволюции психики и не была ею использована. Иерархия в системе памяти — это как бы информационный трансформатор, обеспечивающий преобразование любых объемов внешней информации во внутреннюю с уменьшением до сотен тысяч раз и тем самым — безграничное расширение познавательных возможностей человека.
Но идею иерархического строения памяти не следует трактовать слишком широко. Предполагать наличие в памяти некоего «центра», который бы подчинял себе множество частных иерархических систем знаний, по-видимому, нет оснований [4; 78].
Описанная модель имеет и прямую практическую направленность. Она служит раскрытию структуры механизмов решения задач, формирующихся в памяти в результате обучения и тем самым — созданию условий для их целенаправленного и оптимизированного формирования. Особую актуальность это имеет для компьютеризированного обучения ввиду первостепенной важности для него проблемы оптимизации. Один из путей оптимизации состоит здесь, можно думать, в осуществлении обучения на основе заранее построенной и оптимизированной модели внутренней репрезентации множества способов решения задач, составляющих весь учебный предмет в целом. Предложенную выше модель можно, по-видимому, рассматривать как теоретическую основу при построении таких глобальных моделей для некоторых учебных предметов (например, грамматик родного и иностранных языков).
1. Аткинсон Р. Человеческая память и процесс обучения. — М., 1980. — 528 с.
2. Брушлинский А. В. Психология мышления и кибернетика. — М., 1970. — 191 с.
3. Величковский Б. М. Современная когнитивная психология. — М., 1982. — 336 с.
4. Величковский Б. М., Зинченко В. П. Методологические проблемы современной когнитивной психологии. — Вопр. психол. 1979. № 7. С. 67—79.
5. Выготский Л. С. Собр. Соч.: В 6 т. Т. 2. — М., 1982. — 502 с.
6. Грановская Р. М. Восприятие и модели памяти. — Л., 1974. — 351 с.
7. Денисов А. А., Колесников Д. Н. Теория больших систем управления. — М., 1982. — 287 с.
8. Зинченко В. П., Величковский Б. М., Вучетич Г. Г. Функциональная структура зрительной памяти. — М., 1980. — 271 с.
9. Клацки Р. Память человека. — М., 1978. — 319 с.
10. Клике Ф. Понятие информации и теории информации в психологии: границы и возможности. — Психол. журн. 1980. Т. 1. № 4. С. 29—47.
11. Кликс Ф. Пробуждающееся мышление. — М., 1983. — 302 с.
12. Кореляков Ю. А. О двух моделях распознавания в структуре умственной деятельности по решению задач. — В сб.: Психологические проблемы процесса обучения младших школьников. М., 1978. — 160 с.
13. Линдсей П., Норман Д. Переработка информации у человека. — М., 1974. — 550 с.
14. Ожегов С. И., Шапиро А. Б. (ред.). Орфографический словарь русского языка. — М., 1956. — 1260 с.
15. Рок И. Введение в зрительное восприятие. Т. 2. — М., 1980. — 279 с.
16. Чуприкова Н. И. Принцип словесно-знаковой сигнализации, речевое общение и умственное развитие. — Вопр. психол. 1983. С. 19—29.
17. Шехтер М. С. Зрительное опознание. — М., 1981. — 264 с.
18. Шоломий К. М. Об одном виде саморегуляции мышления. — Вопр. психол. 1979. № 6. С. 78—85.
19. Шоломий К. М. Сопоставление трех способов распознавания. — Материалы VI съезда Общества психологов СССР. Т. I. M., 1983. С. 387—388.
20. Штейнфельд Э. А. Частотный словарь современного русского языка. — Таллин, 1963. — 316 с.
21. Hoffmann I. Das aktive Gedachtnis. Berlin, 1982. 253 S.
22. Shepard R. N. Recognition memory for words, sentences and pictures. — J. Verb. Behav. 1967. V. 6.
23. Selfridge O. G. Pandemonium: A paradigm for learning. — In: The mechanization of thought process. L., 1959. P. 513—531.
24. Standing L. Learning 10 000 pictures. — Quart. J. Exp. Psychol. 1973. V. 25. P. 207—222.
25 Sternberg S. High-speed scanning in human memory. — Science. V. 153. P. 652—654.
26. Townsend J. T. A stochastic theory of matching processes. — J. Math. Psychol. 1976. V. 14. P. 1—52.
27. Underwood B. J., Shaughnessy J. J., Zimmermann J. The locus of the retention differences associated with degree hierarchical conceptual structure. — J. Exp. Psychol. 1974. V. 102. P. 850—862.
Поступила в редакцию 23.III 1984 г.
1 В русском языке слов значительно больше, чем в использовавшемся словаре (изданном, кстати говоря, в 1953 г.). Об этом свидетельствует уже только факт существования словарей большего объема: англо-русский словарь под ред. И.Р. Гальперина содержит около 150 тыс. слов, немецко-русский (с дополнением) под ред. О.И. Москальской — 180 тыс., словарь русского языка В.И. Даля — 220 тыс. слов. Естественно считать, что часть слов языка, отсутствующих в использовавшемся словаре, испытуемым известна.
2 В литературе уже отмечалась несостоятельность модели С. Стернберга при величине алфавита стимулов порядка тысяч [8]. Тем более несостоятельна она в случае миллионных алфавитов. Этот вывод можно, по-видимому, перенести на все неиерархические модели с последовательным сканированием памяти. Например, согласно модели поиска «в памяти при больших наборах сигнальных стимулов» Р. Аткинсона [1; 320], латентный период идентификации одного словоупотребления при чтении составил бы несколько часов. Вопрос о недостаточности малосистемного подхода для анализа поиска в памяти при сложном материале нуждается в специальном рассмотрении. Отчасти он затрагивается в литературе [9].
3 Относительно ситуации чтения можно считать, что использование здесь в качестве эталонов списка возможных словоупотреблений, по-видимому, маловероятно. Это было бы слишком нерационально Имеющиеся в литературе материалы ([3], [9], [21] и др.) позволяют предполагать, что эталонами могут быть некоторые исходные лексические формы, являющиеся носителями понятий, и компоненты словоупотреблений, фиксирующие морфологическую информацию. Входящие в состав распознающей системы процедуры обеспечивают порождение условий для реализации поиска путем трансформации воспринимаемых словоупотреблений в форму, соотносимую с эталонами.